Alle meine Webseiten werden mit Hilfe von Hugo statisch generiert. Für die Arbeit mit Hugo nutze ich schon länger ein eigenes Python-Script, das mir einige Arbeit abnimmt.
Vor ein paar Tagen hat mich jemand gefragt, ob ich das Script nicht öffentlich machen könnte und ich habe das zum Anlass genommen, da mal einige Dinge zu verschönern, damit auch andere Menschen damit etwas anfangen können.
Ich bin kein Programmierer und das Script hat vermutlich eine eher schlechte Qualität. Aber das stört mich nicht, denn es funktioniert (für mich).
Wenn es andere Menschen für sich nutzen können, dann ist das großartig. Wenn nicht, dann ist es auch okay.
Zur Installation des Scripts bitte in die README.md des Projekts schauen.
Konfiguration
In der Konfigurationsdatei ~/.config/hgh/hgh.json gibt es einen Abschnitt für allgemeine Einstellungen und dann je einen Abschnitt pro Website, die mit hgh verwaltet werden soll.
Hier ist hinterlegt, welcher Editor verwendet werden soll, wo die Basisverzeichnisse der Websites liegen, wo die content-Verzeichnisse, welcher Benutzernamen für rsync verwendet werden soll, usw.
Ein Alias macht das Leben einfacher
Damit ich nicht dauernd hgh.py --site blog tippen muss, habe ich für jede meiner Websites in der .bashrc einen Alias erstellt:
alias hgb=`hgh.py --site blog`
alias hgw=`hgh.py --site wiki`
Somit kann ich z. B. mittels hgb -cdb ins Basisverzeichnis des Blogs wechseln.
Was der Hugo Helper (hgh) für mich macht
Allgemeine Infos
Mit --help gibt es eine hoffentlich hilfreiche Hilfe. 😁
Mit hgh.py --sites bekomme ich eine Liste aller Websites und der zugehörigen Basisverzeichnisse. Mit --printconfig wird die ganze Konfiguration ausgegeben.
Verzeichniswechsel
Mit -cdb kann ich ins Basisverzeichnis einer Website wechseln, mit -cdc ins normale Content-Verzeichnis und mit -cdl in ein alternatives Content-Verzeichnis.
Letzeres nutze ich für verschiedene Blogbeiträge im Entwurfsmodus. Denn mein Blog besteht aus mehreren tausend Blogbeiträgen und das Bauen dauert sehr lange. Zum Schreiben von längeren Blogbeiträgen nutze ich dieses Verzeichnis und das Bauen dauert dann nur wenige Sekunden.
Kommentar-Datei
Für Kommentare im Blog nutze mittlerweile eine eigene Implementation, bei der die Kommentare im Page Bundle innerhalb der Datei comments.json stehen.
Mit hgh.py --site blog --create-comments-file wird im aktuellen Verzeichnis eine comments.json-Datei erstellt, die bereits ein Skelett für einen Kommentar enthält. Dazu wird die Info ausgegeben, dass man noch im Front Matter jsoncomments: true eintragen muss. Da es hier im Blog nur sehr selten Kommentare gibt, vergesse ich das sonst und will auch nicht jedes Mal nachschauen, wie die Syntax eines Kommentars ist.
Neuer Blogbeitrag
Diese Funktion nutze ich nur für meinen Blog und kann mit einem kurzen hgb --create "Ein neuer Blogbeitrag bla blub" gleich mehrere Aufgaben automatisieren:
- benötigte Verzeichnisse erstellen
- Slug aus dem angegebenen Titel erzeugen
- Page Bundle erstellen
- Markdown-Datei für den Blogbeitrag erstellen und mit einem Template befüllen
Details dazu, was alles gemacht wird, gibt es in diesem Blogbeitrag.
In der aktuellen Version des Scripts kann ich auch noch mit --template angeben, welches Template verwendet werden soll.
Mit hgh.py --list-templates wird eine Liste aller vorhandenen Templates angezeigt.
Wer das benutzen will, muss den Code dafür im Script anpassen, um alle notwendigen Variablen auch zu befüllen.
Tmux
Bevor ich VSCode für die Bearbeitung meiner Websites nutzte, habe ich dafür den micro-Editor auf der Kommandozeile benutzt. Aus dieser Zeit stammt --tmux, das ein bestimmtes Layout in Tmux startet. Das habe ich aber schon länger nicht mehr verwendet und man müsste es für sich anpassen.
Lokale Vorschau einer Website
Mittels --hugo-server wird der Blog lokal gebaut und auf dem einstellbaren Port zugänglich gemacht. Für das alternative Content-Verzeichnis gibt es --hugo-server-light.
Dazu kann man noch --hugo-server-env angeben, mit dem sich einstellen lässt, welche Umgebung Hugo verwendet. Default hier ist development. Ich nutze diese Funktion, um den umfangreichen Blog testweise so zu bauen, dass nur die Blogbeiträge der letzten Monate enthalten sind, was dann statt 35 Sekunden (für den gesamten Blog) nur ca. 3 Sekunden dauert.
Tags, Kategorien und deren Häufigkeit
Was mir am Anfang bei Hugo im Vergleich zu WordPress sehr gefehlt hat, waren die Vorschläge für zu verwendende Tags und Kategorien in einem neuen Blogbeitrag.
Hierfür muss man mit dem Hugo Helper eine kleine “Datenbank” erstellen lassen. Dazu wird mit Hilfe von find und dem Tool yq je eine Liste aller bisher verwendeten Tags und Kategorien erstellt und dazu auch die Häufigkeit der Verwendung angegeben.
Diese “Datenbank” erstellt man mit hgh.py --site blog --create-tags-categories-caches und das dauert ein paar Sekunden. Im Ergebnis werden innerhalb von ~/.cache/hgh/ für jede Website zwei Dateien erzeugt:
> ls -1 .cache/hgh/
natenom.de_categories.list
natenom.de_tags.list
Ein Auszug aus den Tags:
[…]
8:F-Droid
1:FLAC
4:Facebook
1:Fahrbahn
556:Fahrrad
52:Fahrradanhänger
1:Fahrradbubble
22:Fahrradcomputer
6:Fahrradmordor
6:Fahrradparkplätze
2:Fahrradstaffel
1:Fahrräder
10:Falschparker
[…]
Um nicht manuell in den “Datenbanken” herumstöbern zu müssen, gibt es --find-tags xyz und --find-categories xyz bzw. die Kurzformen -ft xyz und -fc xyz. Man kann reguläre Ausdrücke verwenden.
Führt man diese aus, wird das Tool fzf (Fuzzy Find) benutzt, um die Liste anzuzeigen und darin suchen zu können:
Alles andere finden
Mittlerweile nutze ich zum Auffinden von Blogbeitragen die Tastenkombination Strg + Shift + f in VSCode. Aber früher brauchte ich dafür etwas Eigenes.
Hierfür gibt es zwei Varianten.
Einfache Variante
Mittels --find xyz bzw. der Kurzform -f xyz wird einfach nur rekursiv nach xyz im Content-Verzeichnis der angegebenen Website gegrept und es gibt eine farbige Ausgabe mit Dateinamen und der zum Suchbegriff passenden Zeile. Groß- und Kleinschreibung werden dabei nicht ignoriert.
Hier z. B. das Ergebnis für die Suche nach ^hugo. Das ist ein Regulärer Ausdruck, der nur auf Zeilen passt, in denen hugo am Anfang der Zeile steht:
posts/2022/2022-02-18-mein-workflow-mit-hugo/index.md:130:1:hugo server -E -D -F -v -c /home/hugo-light/content/
posts/2022/2022-02-27-hugo-theme-optimiert-zeit-zum-rendern-massiv-verringert.md:24:1:hugo --templateMetrics --templateMetricsHints --gc --minify > hugo-metric_0.txt
posts/2022/2022-02-06-ich-mache-wieder-einen-linkdump-woechentlich/index.md:64:1:hugo new -k linkdump posts/2022-02-linkdump-kw-6-2022
posts/2022/2022-03-19-umzug-dokuwiki-hugo-3-einrichtung/index.md:29:1:hugo new site wiki.natenom.com
posts/2022/2022-02-03-umzug-von-wordpress-zu-hugo-1/index.md:310:1:hugo server --renderToDisk -D -E -F -v
posts/2022/2022-02-13-weiterleitungen-auf-umlaut-urls/index.md:55:1:hugo-search-tags -E "(ä|ö|ü|ß)" | cut -d':' -f2 > /tmp/umlaut-urls-hugo.txt
So kann ich z. B. sehr einfach alle Blogbeiträge anzeigen lassen, die ein bestimmtes Tag oder eine Kategorie verwenden, hier z. B. “Linux”, in dem ich den Regulären Ausdruck hgb -f "^\W+- Linux" nutze, der auf Zeilen passt, die am Zeilenanfang beliebig viele Leerzeichen enthalten, gefolgt von - Linux:
[…]
posts/2013/2013-06-27-alle-videos-eines-youtube-kanals-auf-einmal-herunterladen-mit-youtube-dl.md:7:1: - Linux
posts/2018/2018-11-12-mit-fensterregeln-in-plasma5-kde-bestimmte-fenster-beim-task-switcher-und-anderen-effekten-ignorieren.md:13:1: - Linux
posts/2013/2013-08-15-neuer-versuch-mit-kde-sc.md:11:1: - Linux
[…]
Erweiterte Variante
Mittels --find-fuzzy xyz bzw. der Kurzform -ff xyz wird die Ausgabe der oben gezeigten einfachen Variante zusätzlich an fzf übergeben, sodass man darin suchen kann, eine Vorschau der Datei angezeigt bekommt und durch Drücken von F4 die Datei direkt im Editor öffnen kann, den man in der Konfiguration in bin_editor eingestellt hat.
Auch hier kann man reguläre Ausdürcke verwenden, z. B. -ff "Markdown.*kate"
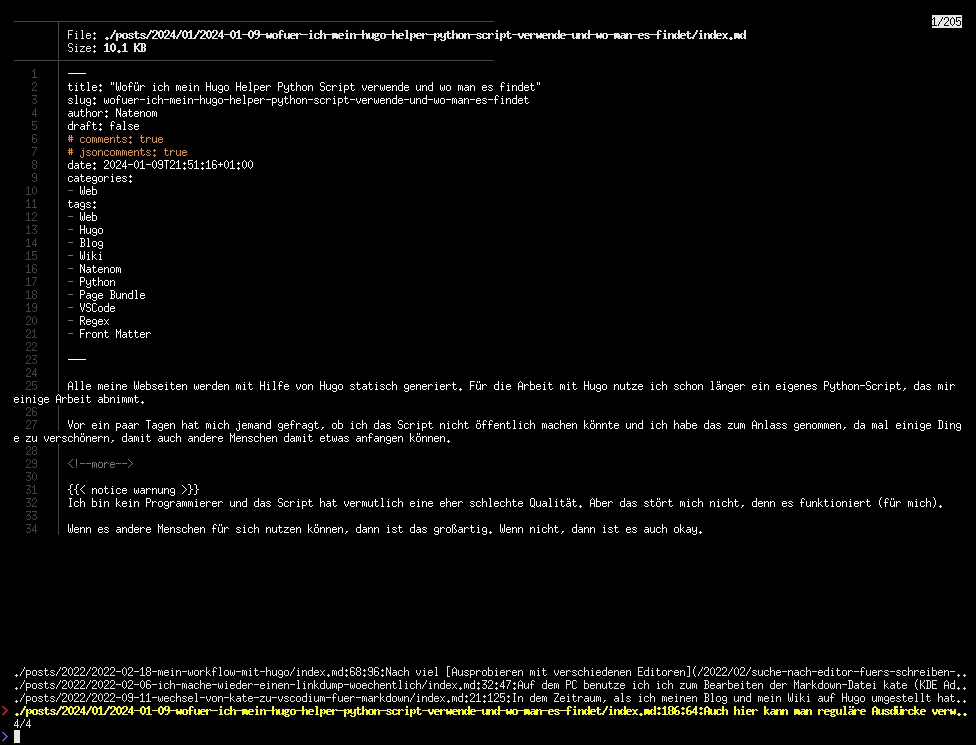
Website bauen und hochladen
Mit hgh.py --site blog --build wird mein Blog lokal gebaut, sodass ich ihn nach einer kurzen Prüfung mit hgh.py --site blog --upload hochladen kann.
Wenn ich mir sicher bin, kann ich auch beide Schritte vereinen mit hgh.py --site blog --deploy.
Hugo Helper herunterladen
Das Hugo Helper Script gibt es hier.
Viel Spaß damit. Oder eben nicht. ☺️
Kommentare
Bisher gibt es hier keine Kommentare.
Kommentar oder Anmerkung für diesen Blogbeitrag
Öffentlicher Kommentar per E-Mail: Hier klicken
Nicht öffentliche Anmerkung per E-Mail: Hier klicken
Sonstige Kontaktaufnahme: Kontakt