Vorab: Das hier ist sehr hacky. Aber ich habe leider keine entsprechenden Kenntnisse, um das richtig umzusetzen. Und da ich ein fauler Mensch bin, reicht mir die beschriebene Lösung aus, um mein Problem zu lösen. Wer etwas Würde hat, macht jetzt am besten diesen Beitrag wieder zu :P
2024-01-06: Ich habe eine verbesserte Variante erstellt, die außerhalb von Hugo funktioniert und sehr viel einfacher, siehe hier.
2022-02-11: Bash-Scripte gefixt, damit sie auch Tags und Kategorien mit Bindestrichen anzeigen.
Was will ich überhaupt lösen?
Mein Problem: In WordPress kann man beim Einfügen von Tags in einen Beitrag direkt Vorschläge sehen, die zum eingegebenen String passen. So wird verhindert, dass es irgendwann verschiedene Schreibweisen von Tags gibt und man immer die selben Tags verwendet.
In Hugo gibt es das natürlich nicht. Zumindest habe ich dazu nichts gefunden. Deshalb möchte ich eine Liste aller Tags angezeigt bekommen, die bisher allen vorhandenen Blogbeiträgen verwendet wurden und dazu auch noch die Anzahl der Vorkommen.
Ich könnte jetzt anfangen, $Suchmaschine zu benutzen und mir in Python irgendwas zusammen zu coden. Ich bin für die einfachere Möglichkeit. Denn schließlich zeigt das bei mir im Blog verwendete Theme bereits die Tags und Kategorien an und und sogar, wie oft diese verwendet wurden. Hugo kann also die Arbeit für mich machen.
Die Ideallösung wäre, wenn ich eine json-Datei erstellen lassen könnte mit diesen Informationen. Wie man so etwas macht, konnte ich leider nicht herausfinden. Ich bin Anwender, kein Programmierer.
Ultra hacky ab jetzt :P
Letzte Warnung: Mach hier zu, wenn du noch etwas Würde behalten möchtest :)
Zuerst erstellt man einen Shortcode in layouts/shortcodes/ mit dem Namen _internal-cats-tags.html mit folgendem Inhalt:
{{ range $.Site.Taxonomies.categories.ByCount }}
internal_category:{{ .Name }}:{{ .Count }}:
{{end}}
{{ range $.Site.Taxonomies.tags.ByCount }}
internal_tag:{{ .Name }}:{{ .Count }}:
{{end}}Es ist Absicht, dass hier eine Textliste und kein HTML generiert werden soll. So muss man später weniger filtern.
Danach erstellt man in contents/ eine Datei _internal_cats_tags.md mit diesem Inhalt:
---
title: internal-only-cats-tags
date: 2022-02-08T02:43:20+01:00
---
{{< _internal-cats-tags >}}
Die Datei ist sollte jedoch am besten noch auf Entwurfsmodus eingestellt werden, also den Wert true im Tag draft haben, um nicht auf der veröffentlichten Website zu landen.
Dann lässt man Hugo die ganze Website rendern (Schalter -D für den Hugo-Aufruf nicht vergessen, damit Drafts auch gebaut werden) und erhält die Datei public/_internal_cats_tags/index.html.
Ergebnis
So sieht die generierte Seite aus:

Und so sieht der Quelltext aus:
[…] internal_category:643:allgemein: internal_category:416:mobilität:
internal_category:332:fotografie: internal_category:326:mumble:
internal_category:274:musik: […] internal_tag:761:open-source:
internal_tag:525:fahrrad: internal_tag:368:fotos:
internal_tag:348:creative-commons: internal_tag:335:mumble:
internal_tag:326:mobilität: internal_tag:292:musik:[…]
Aus dieser Seite kann man nun die Daten filtern.
Daten filtern und in neue Dateien schreiben
Jetzt kann man die Kategorien und die Tags herausfiltern und in neue Datien schreiben.
Nach Kategorien filtern
grep -i -E "^internal_category:[0-9]{1,4}:[a-z0-9-]*:$" public/_internal_cats_tags/index.html | sort -r -V | uniq | cut -d':' -f2,3 > _list-categories.txt
Ergebnis:
643:allgemein
416:mobilität
332:fotografie
326:mumble
274:musik
225:linux
162:web
94:android
66:spiele
34:linkdump
Tags
grep -i -E "^internal_tag:[0-9]{1,4}:[a-z0-9-]*:$" public/_internal_cats_tags/index.html | sort -r -V | uniq | cut -d':' -f2,3 > _list-tags.txt
Ergebnis:
525:fahrrad
368:fotos
335:mumble
326:mobilität
292:musik
256:linux
241:pforzheim
215:videos
213:natur
206:filme
[...]
Helfer für die Bash
In die .bashrc kommt hinein:
export HUGO_WORKDIR="/home/natenom.de-hugo"
function hugo-check-and-write-cats-tags (
cd $HUGO_WORKDIR
test -f public/_internal_cats_tags/index.html && \
grep -i -E "^internal_category:[0-9]{1,4}:[a-z0-9]*:$" public/_internal_cats_tags/index.html | sort -r -V | uniq | cut -d':' -f2,3 > _list-categories.txt && \
grep -i -E "^internal_tag:[0-9]{1,4}:[a-z0-9]*:$" public/_internal_cats_tags/index.html | sort -r -V | uniq | cut -d':' -f2,3 > _list-tags.txt && \
echo "Updates written" || \
echo "File is not available, no updates."
)
alias hugo-search-tags='cd $HUGO_WORKDIR; cat _list-tags.txt | grep -i '
alias hugo-search-categories='cd $HUGO_WORKDIR; cat _list-categories.txt | grep -i '
Wenn ich den Eindruck habe, dass die extrahierten Daten veralten sein könnten, rufe ich in der Shell hugo-check-and-write-cats-tags auf, sobald die komplette Website generiert wurde.
Suchfunktion
Jetzt kann ich nach Tags suchen:
$ hugo-search-tags oliz
66:polizei
3:polizeipräsidium
2:polizeipräsidentin
Und nach Kategorien:
$ hugo-search-categories ""
643:allgemein
416:mobilität
332:fotografie
326:mumble
274:musik
225:linux
[…]
Und im KDE Advanced Text Editor (kate) kann ich dann direkt mit F4 eine Konsole öffnen und nach Kategorien und Tags suchen, während ich das Front Matter bearbeite.
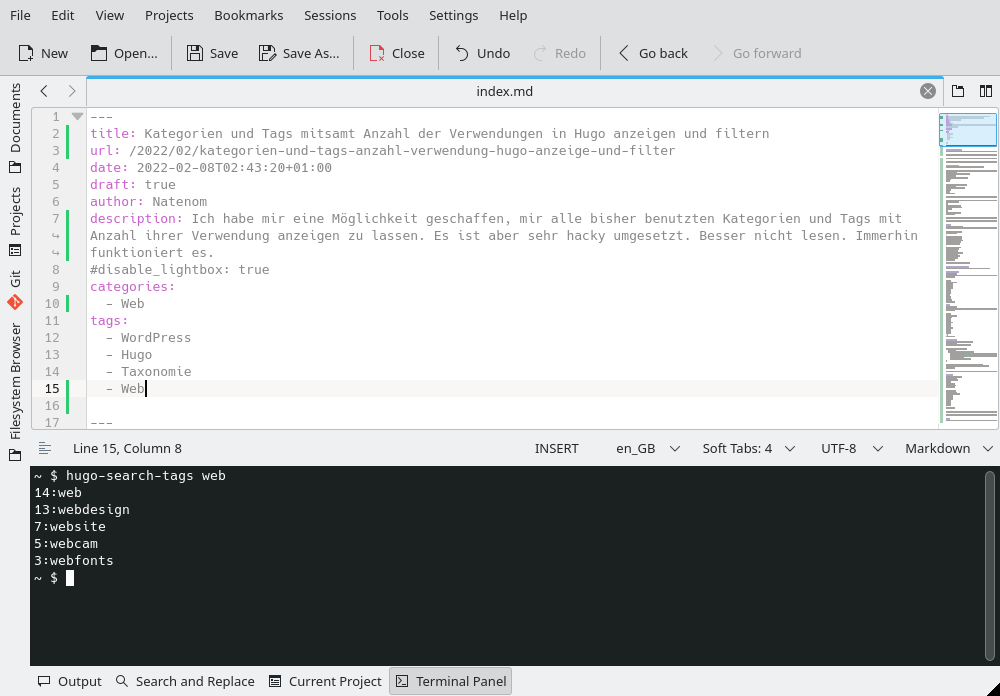
Später
Und irgendwann mal, später, also irgendwann später, mache ich das dann auch so, dass man sich nicht für die Lösung schämen muss. Ganz bestimmt.
Kommentare
Bisher gibt es hier keine Kommentare.
Kommentar oder Anmerkung für diesen Blogbeitrag
Öffentlicher Kommentar per E-Mail: Hier klicken
Nicht öffentliche Anmerkung per E-Mail: Hier klicken
Sonstige Kontaktaufnahme: Kontakt